This menu item is not available for Free plan users.
In Bosch IoT Insights, pipelines are the key functionality to process data. A pipeline can be seen as a configurable piece of logic between your incoming data and the database.
Pipelines provide a basic set of building blocks that you can use to tailor the data to your specific needs. Data sets can be decoded using decoder formats, such as ODX, FIBEX, A2L, and DBC. Each data set is checked for errors, omissions, and inconsistencies. Before processing, the data sets are cleaned up to ensure the validity and suitability for further processing. Data sets are then transformed to a uniform structure.
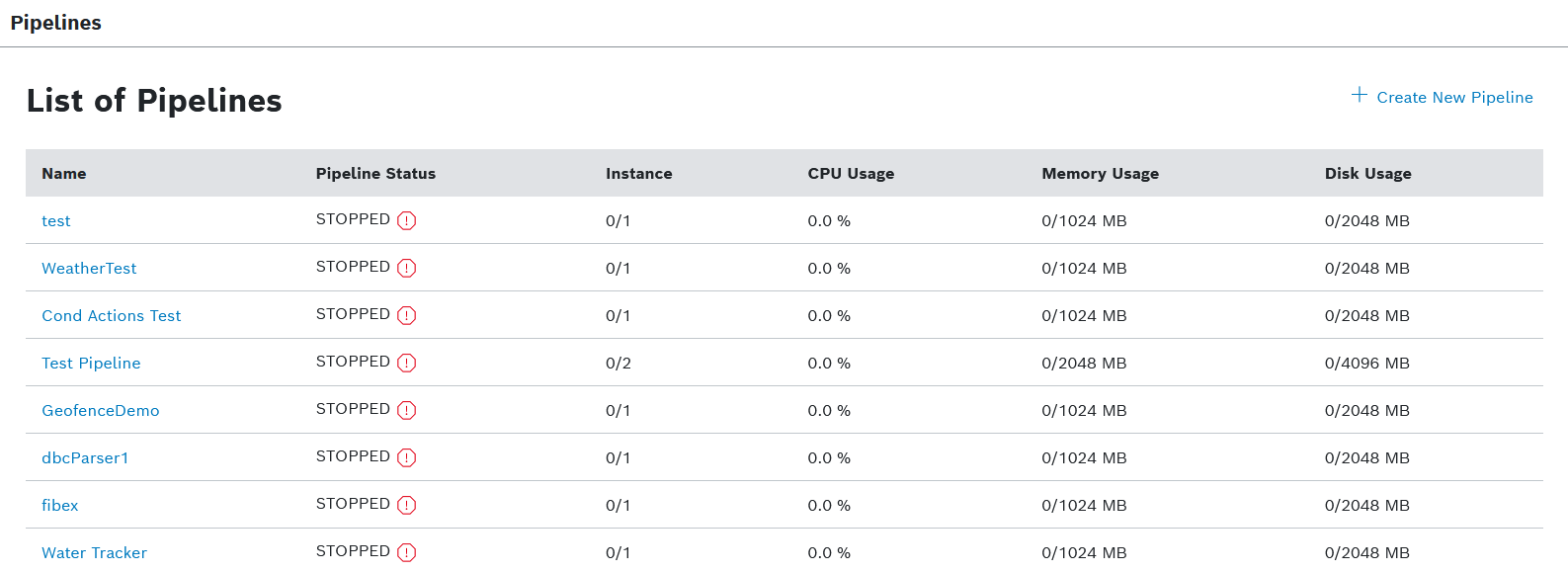
This chapter details the following topics:
Prerequisites
- You are assigned to the Power User role.
- For Pay As You Go plan projects: If dedicated pipelines are required, these must be activated by an Admin:
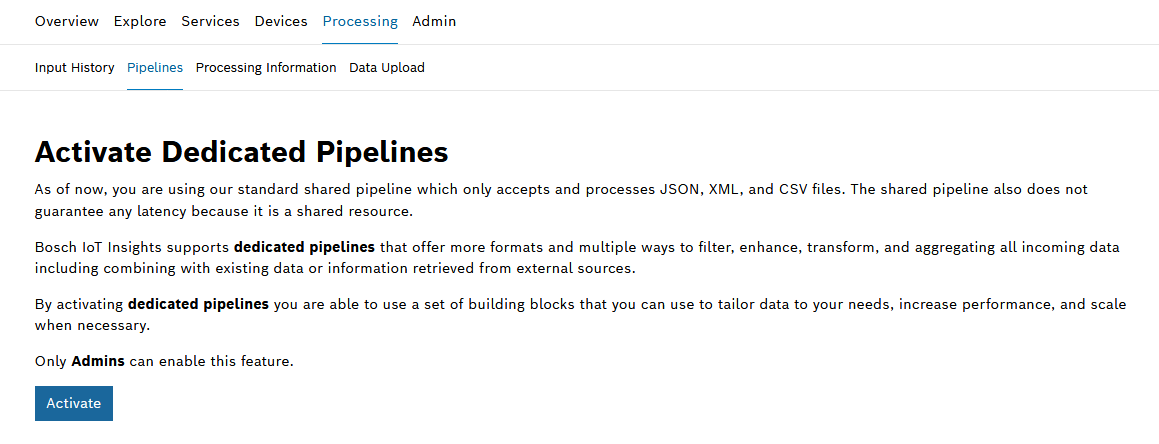
Pipeline components
A pipeline consists of three components:
- Pipeline App
- Pipeline versions
- Processing steps
Pipeline App
The Pipeline App is a container in which code is stored and can be executed. It has a set of instances, RAM, and disc space. The processing speed can be influenced by scaling it up or down. A higher memory limit also can increase the CPU performance. The reason for this is that if the memory limit is increased, more CPU cycles are reserved for the related Pipeline.
Pipeline versions
A pipeline version holds a specific configuration of the pipeline. Such a version is created automatically by the system every time when a configuration is saved or the pipeline information is updated. For each pipeline, multiple pipeline versions can be stored but only one can be set to active. It is also possible to revert to former versions of a stopped pipeline. Refer to Managing pipeline versions.
Processing steps
Processing steps are a set of checkpoints that your data will pass until stored in the database. Several processing steps are provided that can be used as templates and may be extended.
Bosch IoT Insights provides a Default Pipeline that consists of a pipeline version and the three main processing steps Input Step, Parser Step, Output Step. The incoming data passes through each of these steps.
Currently the following steps are available:
- Input Step
The first step of the pipeline. A MongoDB filter can be defined that allows to choose a time for processing incoming data. - Parser Step
A parser transforms data into exchange data. A set of functions is available, such as JSON, ZIP file, CSV, etc. - Additional steps:
- Custom Event
In the custom event step, you can write a query condition. If the condition is fulfilled, the incoming data to this step will be used to produce the configured custom event. - Custom
In the custom step, a code artifact can be uploaded that controls the data processing. A code artifact is an assembly of code and project files that form the business logic. As of now support for Java and Python is provided.
In the Examples chapter, you can find information on how to configure the custom step, refer to Pipelines: Configuring the custom step. - Labeling
In the labeling step you can define a condition query in order to match documents and apply labels to them. The labels will be set in the documents' meta data. - Parser
You can add an additional parser as needed. - Device Position
In a device position step, the GPS coordinates of a device are extracted and stored in its digital twin representation. This can be used also for geofence scenarios.
- Custom Event
- Output Step
The last step of the pipeline. The collection to store the processed data in can be specified.
Processing architecture
The basic data flow for a pipeline is shown in the following. Data is sent from a device or via an HTTP call to Bosch IoT Insights. At first, the raw data is stored into the Input Data collection. The pipeline's input step will now decide how to process the data. You can then upload custom code or use other steps.
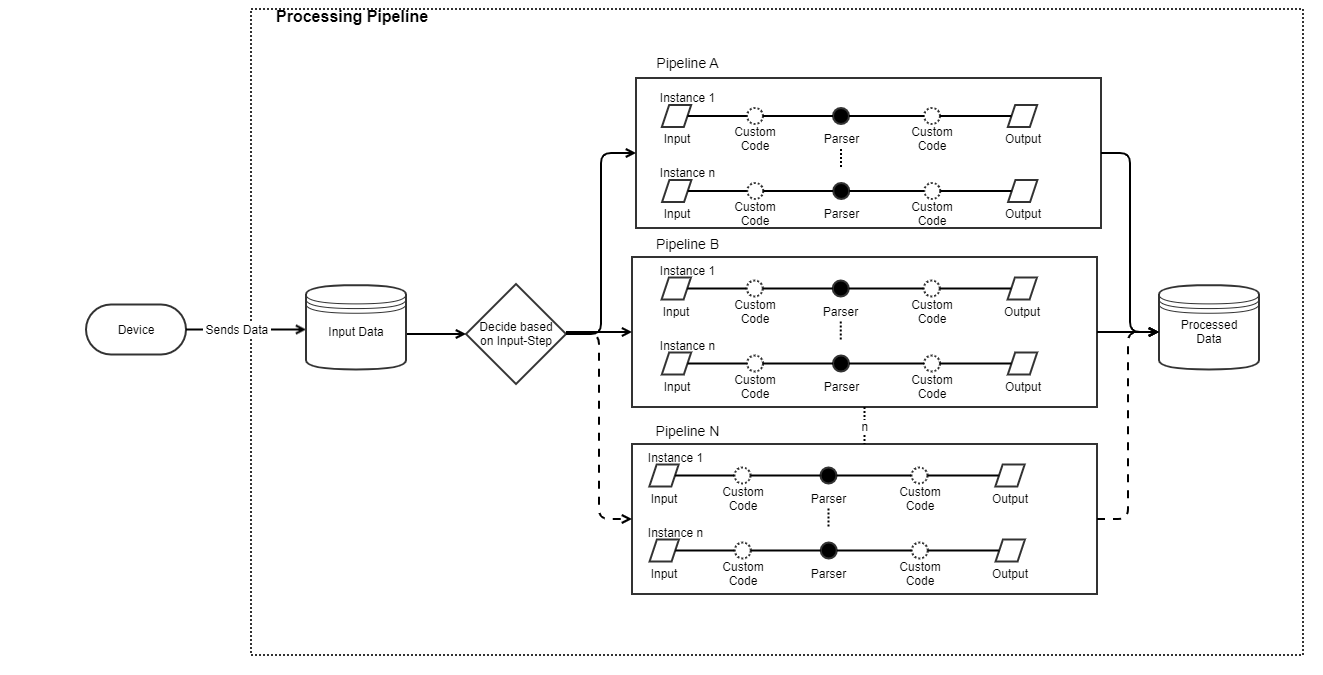
Pipeline system updates
The pipeline is an app that runs on an underlying runtime platform. When the pipeline app or the runtime platform is updated, the pipeline will perform an automated restart.
To avoid random restarts, there is a maintenance window which is used to apply updates and pipeline restarts.
During a restart, the pipeline shortly stops processing data. The pipeline has a 30 second grace period to finish processing the current item. If the processing of a single item takes longer than the grace period, it will likely fail during a pipeline restart and will not be reprocessed automatically.
For input trigger based processing, the pipeline will continue where it left off. For document trigger based processing, all events that occurred during a pipeline downtime are lost. To reduce the likeliness of losing events, we recommend using multiple pipeline instances for document trigger processing.
General functions
Creating a pipeline
Refer to the Creating a pipeline chapter.
Viewing, editing, and reverting pipeline versions
Refer to the Managing pipeline versions chapter.
This chapter details the following topics: